
In the last several weeks I saw a lot of posts showcasing demos/products on how to use AI algorithms for recognizing people who are not wearing masks. In this post, I will take you through a very simple approach to show how can you build one yourself and also end by asking few questions that can help in building a product that can be used for production. We will be using PyTorch for this task, but the steps would remain almost the same if you are trying to achieve it using another framework like TensorFlow, Keras, or MxNet.
To build any AI algorithm, the most common approach is to
- Prepare a labeled dataset.
- Choose an architecture that suits your needs. Preferably pre-trained based on your use-case.
- Train the model and test the model.

I will try to cover only the important details in the post. Most of the code should be self-explanatory and is made available to you on our github repository

Prepare a Labelled Dataset
We need images/videos that contain people with and without wearing masks. Quick research showed no publicly available data. So I decided to annotate the training images manually along with my 4-year-old son. But for someone who has been doing deep learning for a while, I do not want to follow a completely manual approach to annotate the dataset. Remember we need 4 points for each person in an image along with whether the person is wearing a mask or not. This could be a very laborious task. An example of this would look like below.

To make our lives easier, I came up with a semi-autonomous approach. Most of the pre-trained models on object detection are trained on a dataset called coco and fortunately, the first category in it is person. So we can use any pretrained model to generate bounding box coordinates and we can manually record if the person in the bounding box is wearing a mask or not.
To prepare the dataset we would take a 3 step approach.
- Capture frames from some video containing persons wearing and not wearing masks.
- Use a pre-trained model to annotate persons not wearing masks.
- Prepare a Pytorch Dataset and Dataloader.
Prepare Data from a Video
I just took a video from a news article and extracted 1 frame per second.
video = cv2.VideoCapture(file)
fps = video.get(cv2.CAP_PROP_FPS)
img_files = 0
while True:
for i in range(29):
(grabbed, frame) = video.read()
if grabbed: img = frame
if not grabbed or i ==28:
cv2.imwrite(f'input_frames/{img_files}.jpg',img)
img_files += 1
break
if not grabbed:break
In the above code, we read a video file using the popular cv2 library and loop through it to capture a single frame per second. The particular video had 29 frames per second, if you are using a different video you may have to adjust this parameter.
Annotate using a semi-automatic approach.
torchvision comes with a popular object detection model called Faster R-CNN which we will use for generating bounding boxes.
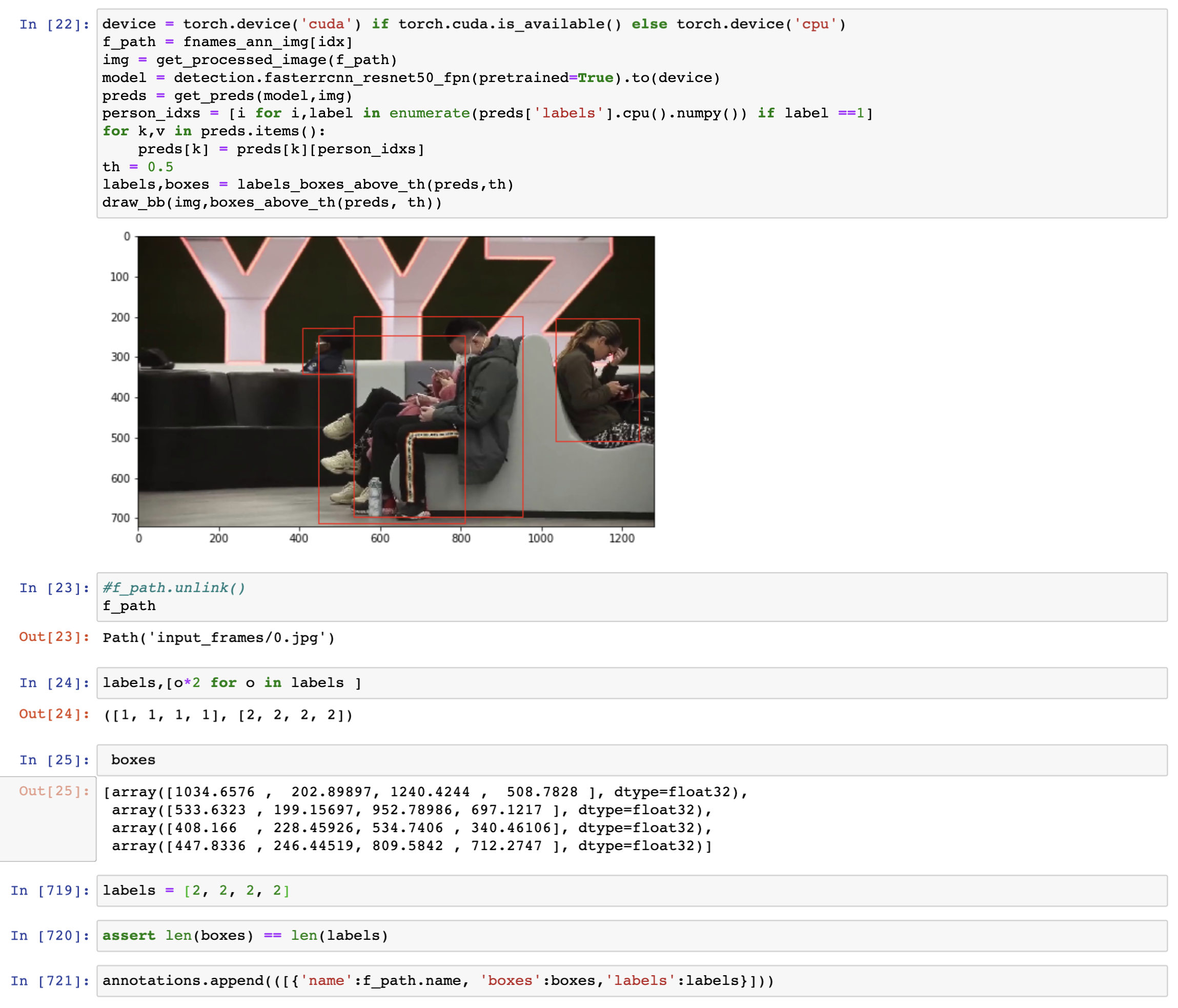
If you are new to object detection check out this PyTorch tutorial.
We run the above code and manually change the value of labels in cell number 719. Label 1 represents persons not wearing masks and 2 represents persons wearing masks. For the sake of convenience, whenever it is not clear, particularly for a person showing their back, I mark its label as a person wearing a mask.
Creating a Dataset and Dataloader.
Since the number of hand-annotated images is less I want to use another approach to increase our training dataset. To do this I include another publicly available dataset containing pedestrians walking on the road. There is a very high probability that these pedestrians did not wear masks as the data was annotated much before Covid-19 times.
The dataset contains masks for each person in the image, so we first extract bounding boxes and label them as persons with no masks.
person_dataset = []
for i,masks_path in enumerate(fmasks):
msk = Image.open(masks_path)
msk = np.array(msk)
obj_ids = np.unique(msk)[1:]
masks = msk == obj_ids[:,None,None]
boxes = []
num_objs = len(obj_ids)
for num in range(num_objs):
pos = np.where(masks[num])
x_min = np.min(pos[1])
x_max = np.max(pos[1])
y_min = np.min(pos[0])
y_max = np.max(pos[0])
boxes.append([x_min,y_min,x_max,y_max])
assert num_objs == len(boxes)
boxes = np.array(boxes)
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
iscrowd = np.zeros((num_objs,), dtype=np.int64)
labels = np.ones((num_objs,), dtype=np.int64)
person_dataset.append({'name':fnames[i],'boxes':boxes,'labels':labels,'area':area,'iscrowd':iscrowd})
Now we have to just club the 2 separately annotated data samples and create our final training dataset.
class MaskNoMaskDataset(torch.utils.data.Dataset):
def __init__(self,ds,transforms=None):
self.ds = deepcopy(ds)
self.transforms = transforms
def __getitem__(self,idx):
o = deepcopy(self.ds[idx])
img = Image.open(o['name']).convert('RGB')
image_id = torch.tensor([idx])
boxes = torch.from_numpy(o['boxes']).type(torch.float32)
area = torch.from_numpy(o['area']).type(torch.float32)
labels = torch.from_numpy(o['labels'])
iscrowd = torch.from_numpy(o['iscrowd'])
target = {'boxes':boxes,'labels':labels,'image_id':image_id,'area':area,'iscrowd':iscrowd}
if self.transforms is not None:
img, target = self.transforms(img, target)
return img,target
def __len__(self):
return len(self.ds)
indices = torch.randperm(len(dataset)).tolist()
dataset = torch.utils.data.Subset(dataset, indices[:-2])
dataset_test = torch.utils.data.Subset(dataset_test, indices[-2:])
Model creation and training
We choose the fasterrcnn model from torchvision for this post as the official Pytorch website has a nice tutorial showing how to fine object detection pipeline. Let's understand the Faster R-CNN model from a very high level. It has a 2 step object detection pipeline. The first one is the region proposal primarily responsible for generating crops of images that could potentially contain objects of our interests. The second one is a classifier that predicts if a particular object is present.
model = detection.fasterrcnn_resnet50_fpn(pretrained=True)
num_classes = 3
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features,num_classes)
Training
We use the utility classes that come with torchvision to finetune our model. I trained the model for 30 epochs, which took less than an hour on the titan x card.
for epoch in range(num_epochs):
train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq=10)
# update the learning rate
lr_scheduler.step()
# evaluate on the test dataset
evaluate(model, data_loader_test, device=device)
Testing
If you have noticed, we would have just used 2 images for the testing dataset. This is not a good practice, but it is ok in our case as we have very little training data. The truth is it takes a lot more effort to make these models usable in the real world.
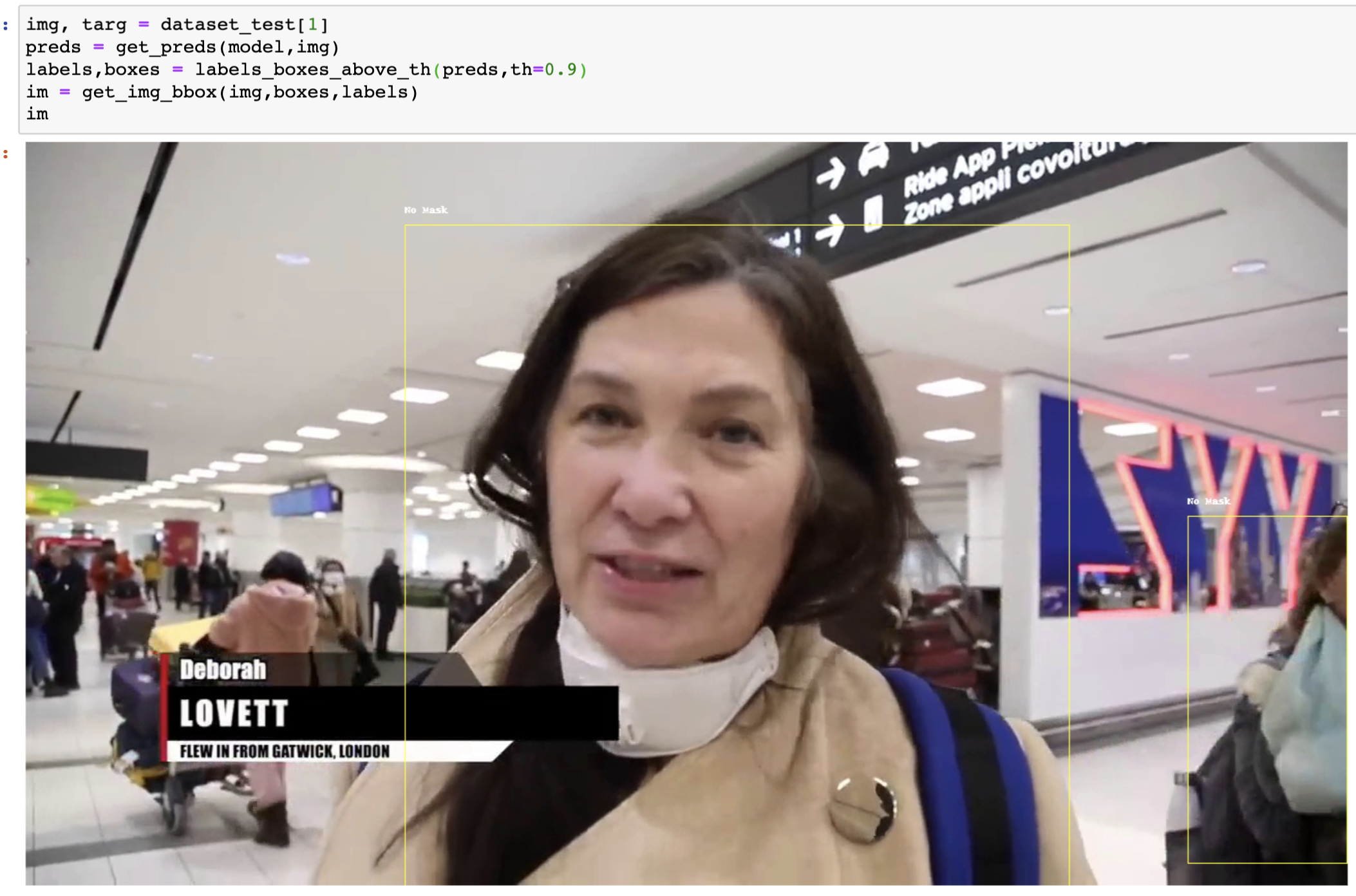
Not bad, but could it be because of leakage from the training data. So I just took another image from LinkedIn and tested the algorithm, which resulted in the below image.

Note: To be honest I tweaked with the NMS threshold to make the results good.
Note: If any on of you are in this photo and you don't want the image to be used, please let us know. If you are fine with us using it, thanks for the pose.
Conclusion
In the above post, we saw a simple approach by which we can use object detection to identify persons not wearing masks. I saw a few demos similar to this in recent times on different media channels.

Even if we keep privacy violations ahead and think of making such an algorithm useful we need to make some major improvements to make these algorithms useful. Some of the improvements that I could think of are
Match person identified as not wearing a mask with some metadata information like Adhar, Employee ID. Building such a system for a large country could be a very challenging task. But it is possible in a closed environment like office space, factories.
Avoiding duplication - This is a critical problem that has to be solved before making algorithms like these useful. The majority of the object detection algorithms available do not use context like humans do, which will make the algorithm recognize the same person multiple times.
Cost - Models like Faster R-CNN are computationally expensive. So it is important to build an algorithm that is computationally cheaper and can run on edge devices.
Check for Bias - The model learns from what it sees. And most of the publicly available training datasets may not represent the different types of persons we meet in the real world. This can create some crazy results like identifying people with a large beard as having masks, it also gets confused with people who have a specific white skin tone. There could be many more. So it is very important to keep an eye on these situations.
Adversarial Attacks - The model can find it very difficult to identify people having masks around necks and not properly covering their faces.
The field of object detection is going through some big changes in 2020 (DETR), we will go through them in the future posts and also understand some of these models in depth.
If you want to quickly try out this project or build your next cool project then check out JarvisCloud - A simple and affordable GPU cloud platform.