
Introduction
In this competition, we will be predicting answers to questions in Hindi and Tamil. The answers are drawn directly from a limited context given to us for each sample. The competition is diverse and unique compared to other competitions currently held on Kaggle focusing on Multilingual Natural Language Understanding (NLU), which makes it difficult and exciting to work with. Hence, the task of this competition is to build a robust model in which you have to generate answers to the questions about some Hindi/Tamil Wikipedia articles provided.
This blog explains the problem statement and how to start with the Kaggle competition chaii - Hindi and Tamil Question Answering hosted by Google Research India.

About Dataset
We are given three CSV files containing train data, test data, and sample submission.
train.csv
It is the dataset with the help of which, we will train our models. Contains context, questions, and their valid answers(ground truth) along with a column answer_start (refers to the initial position of answer in context).
test.csv
It is the dataset on which our model will make predictions consisting of context and Questions.
sample_submission.csv
This file is provided by the host to provide the correct submission file format which has to be used to get a valid score on the leaderboard.
The training set is very small includes 747 Hindi and 368 Tamil examples
The submission file should consist of 2 columns:
id: Unique IDPredictionString: Predicted String
Understanding Evaluation Metric - Jaccard Score
In this competition, our submissions will be evaluated on the Jaccard Score metric.
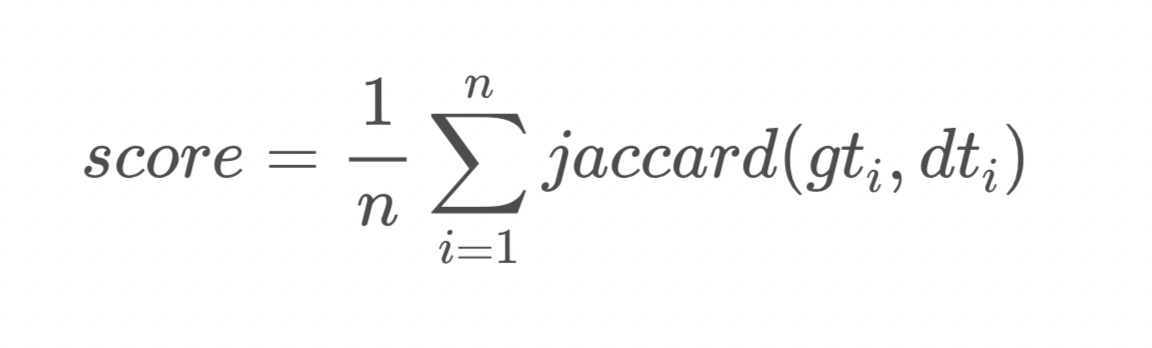
Jaccard score is a measure of similarity considering the overlap of elements. It scores between 0 (no overlap of elements) to 1 (all elements overlap)._
Code to calculate Jaccard between strings
def jaccard(str1, str2):
a = set(str1.lower().split())
b = set(str2.lower().split())
c = a.intersection(b)
return float(len(c)) / (len(a) + len(b) - len(c))
Let’s do some experiments for a better understanding of the metric function.
prediction = 'This is my first blog'
true label = 'This is'
Jaccard score: 0.4
In the above prediction, two words are completely overlapping with the true label,
therefore Jaccard score becomes 2/(5+2–2) = 0.4
prediction = 'This is my first blog'
true label = 'my is first This blog'
Jaccard score: 1.0
The order doesn’t matter, this is one of the key things about the metric.
prediction = 'This is my first blog'
true label = 'my is not'
Jaccard score: 0.33
Getting excessive False-positive also penalizes the Jaccard score. So, having the right amount of length of words is also necessary.
Public Baseline Notebooks
I would love to mention some of the amazing notebooks shared by the Kaggle community with which one could start a strong baseline.
Chaii QA - 5 Fold XLMRoberta Torch - By Rohit Singh
This is a complete package in this competition for anyone looking for a strong baseline to start with. Notebook is based on the Pytorch framework. It includes many latest training strategies. It also includes the usage of external datasets (MLQA, quad).
chaii QA - 5 Fold XLMRoberta Torch | Infer
Hello friends chaii pi lo - By Abhishek Thakur**
Another amazing notebook was published by none other than Quadrapule Grandmaster Abhishek Thakur. Similar to Rohit's baseline, this one is also based on the Pytorch framework and also uses external datasets.
EDA Notebooks
I have already briefed a lot about the competition, but if you are willing to know about the competition more, these are some of the great notebooks one could refer to.
- EDA - By Darek Kłeczek
- chaii-QA: Character/Token/Languages EDA 🕵️ - By Nicholas Broad 🐢
- 🔥Chaii - EDA and Preprocessing(Weights & Biases) - By TensorGirl
Key Suggestions For A Strong Finish
Transformers is all you need
Multilingual Transformer models pre-trained on SQUAD data are completely dominating the competition. Some of the models which you could finetune on competition dataset.
- XLM-Roberta-large
- Muril-Large-Cased
- bert-base-multilingual-cased-finetuned-squad
- bert-multi-cased-finedtuned-xquad-tydiqa-goldp
- bert-multi-cased-finetuned-xquadv1
- bert-multi-uncased-finetuned-xquadv1
- mT5-small-finetuned-tydiqa-for-xqa
- xlm-multi-finetuned-xquadv1
External Dataset
Given such a small amount of data for training (~1000 samples), having the right external data could be a key thing to improve the learning of models.
Post Processing
Several post-processing techniques could be used to generate better predictions which include removal of special characters, unnecessarily occurring words in prediction string, having an answer length limit, etc.
Noise-free Dataset**
The training dataset provided by the hosts has many samples having targets labeled incorrectly, this made it difficult to train a model without fixing the labels manually or generating additional data.
Prevent Overfitting
There are very few samples in test data as well. So, even a change in a few predictions could vary score a lot. Having the right validation scheme, a better correlation between validation and public leaderboard score is necessary.
Seq2Seq approach**
Currently most of the teams are predicting starting and ending indexes of the answers. Using a sequence to sequence approach could be helpful in the competition by using an autoregressive model for generating answers.