
Introduction
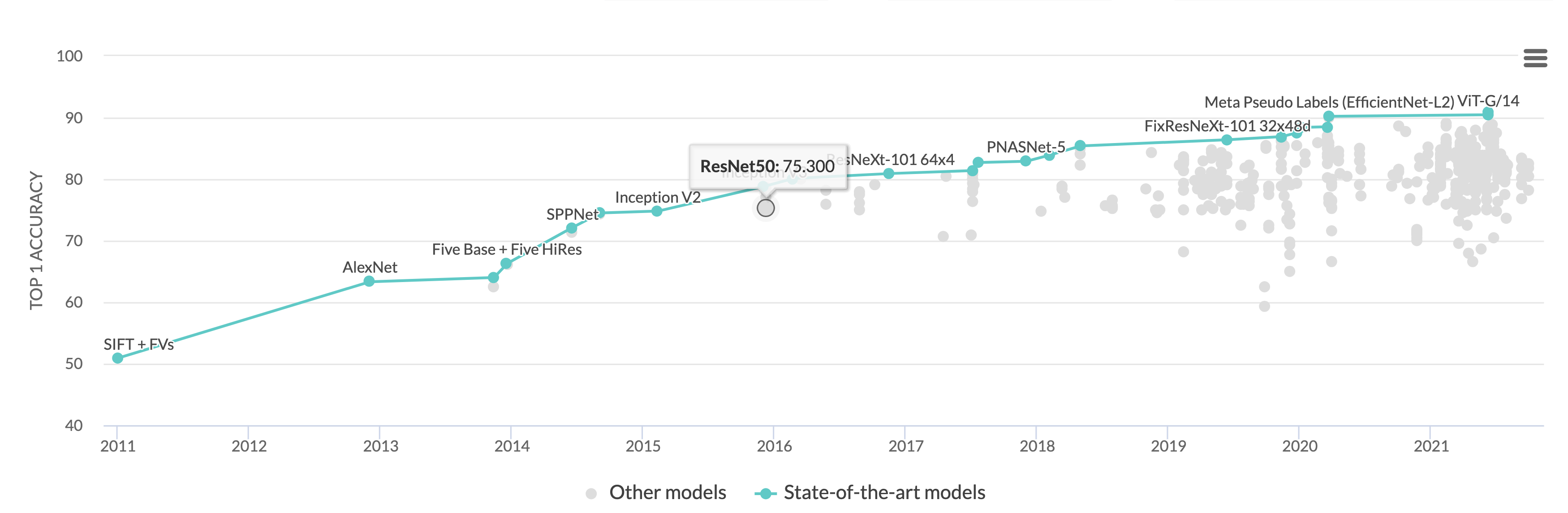
Most of the modern architectures proposed in Computer Vision use ResNet architecture to benchmark their results. These novel architectures train with improved training strategy, data augmentation, and optimizers.

In the ResNet Strikes Back paper, the authors retrain a ResNet50 model with modern best practices and achieve a top-1 accuracy of 80.4% from the standard 75.3% top-1 accuracy.
It is common to observe the performance of a model in isolation, but it depends on three factors,
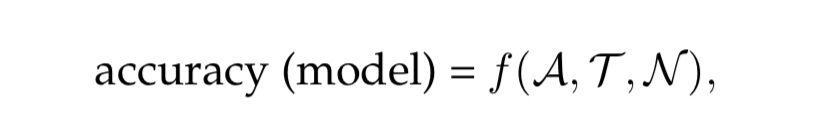
- A - Architecture
- T - Training settings
- N - Noise - Selecting maximum score over a set of hyperparameters
As the performance of the model is dependent on model design and training settings, the training procedures that worked for a particular model may not produce the best results for another model.
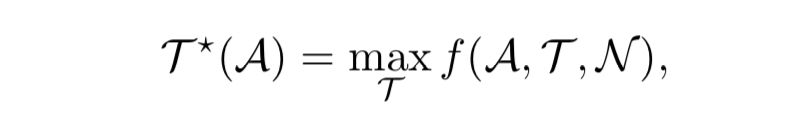
In an ideal case, we would compare a model design with different training settings and choose the one that attains the maximum score. But training a model with many training settings is not practically workable due to the high cost and time factor involved.
In this paper, the authors train a ResNet50 model with different training settings that includes rigorous hyperparameter search to improve the model performance. So future papers can utilize this architecture as a benchmark rather than comparing the ResNet50 trained with older/weaker recipes.
The significant contributions of the paper include
- Three training schedules producing a strong Vanilla ResNet-50 model trained for 100, 300, and 600 epochs.
- Instead of using cross-entropy loss, binary cross-entropy was used.
- The model is trained across various seeds to determine the stability of the accuracy. (An expensive task 🙂)
- To compare model performances, the models and training settings need to be optimized together. The authors discuss how other models behave with the training strategies that worked for ResNet-50.
Training Procedures
Train ResNet-50 with three different training strategies shown below.

Loss
Instead of using typical Cross-Entropy loss, authors use BCE loss with MixUp/CutMix augmentation. With Cross-Entropy loss, the model tries to predict the probability of all the categories. The observation says that treating the Imagenet problem as a multi-label classification problem gains higher accuracy, even when trained with MixUp/CutMix augmentations.
Data Augmentation
On top of Standard strategies like Random Resized Crop, Horizontal flip authors apply Timm variant of RandAugment, Mixup, and CutMix.
Regularization
While training models for longer epochs authors use more regularization. For example, Label smoothing was used only when training the model for 600 epochs.
Heavier augmentations are used only with longer training schedules as they can be harmful when training for a shorter duration. Hence, Repeated Augmentation and stochastic-Depth are adopted only with A1 and A2 training schedules.
When training a larger model like ResNet-152/ResNet-200, the same need not be correct. For example, ResNet-152 models' performance improves by applying more augmentations like RandAugment and MixUp.
Optimization
Cosine schedule + LAMB gave consistently good results, particularly for larger batch sizes(for example, 2048).
For smaller batch sizes, optimizers like SGD and AdamW were good enough.
Experiments
The training procedure A1 performs better than the current SOTA with ResNet-50 on an image resolution of 224 X 224. A2, A3 achieves a better result than many other strategies at a significantly low computational cost.
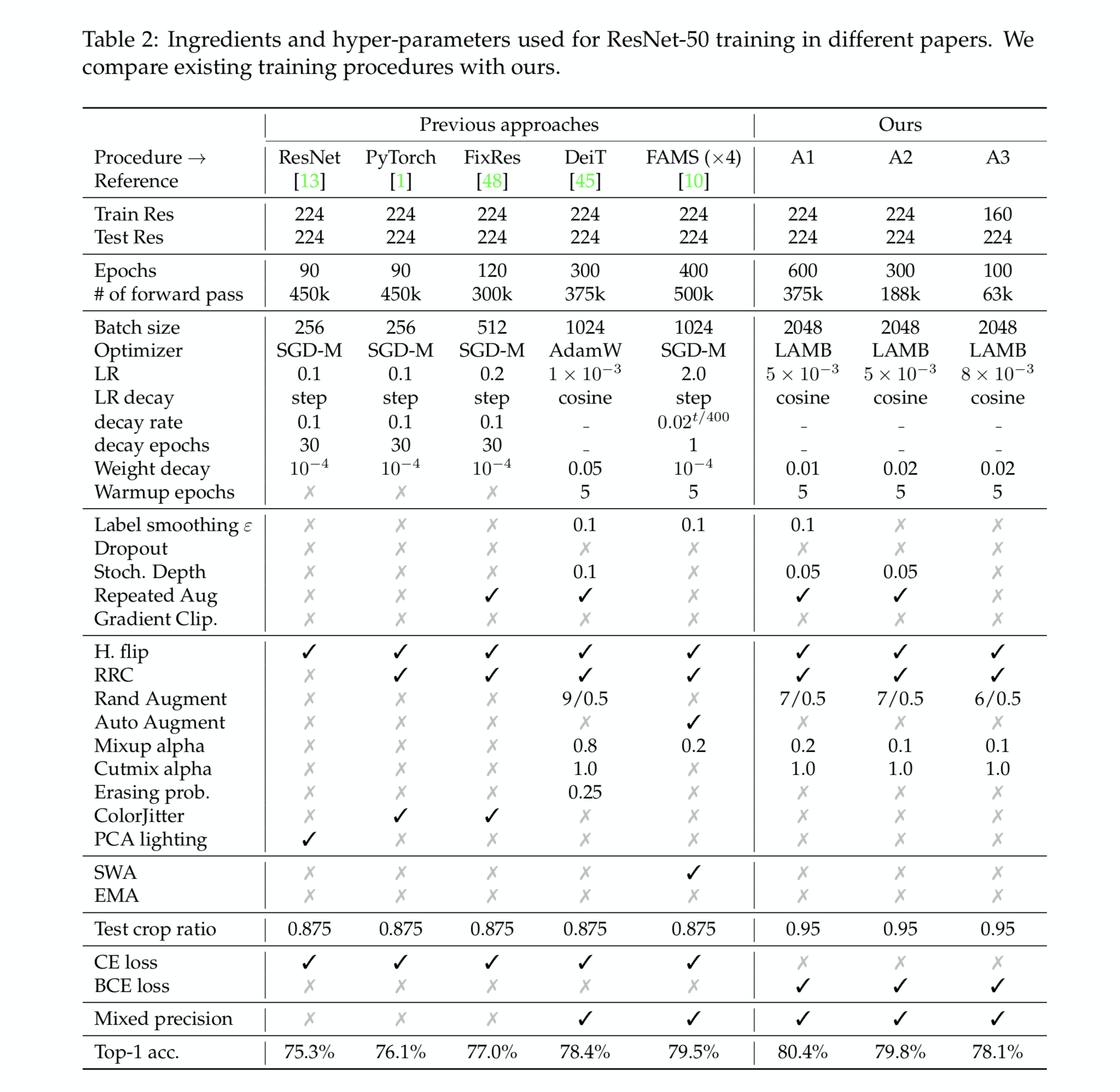
The table below compares the key training steps in the previous procedures like original ResNet, FixRes, and DieT along with A1, A2, and A3 strategies.
Some of the points to be considered from my observation are
- Batch size of 2048
- High weight decay
- 600 epochs for A1.
This table acts as a good checklist when designing training strategies for most of the deep learning problems, particularly in CV.
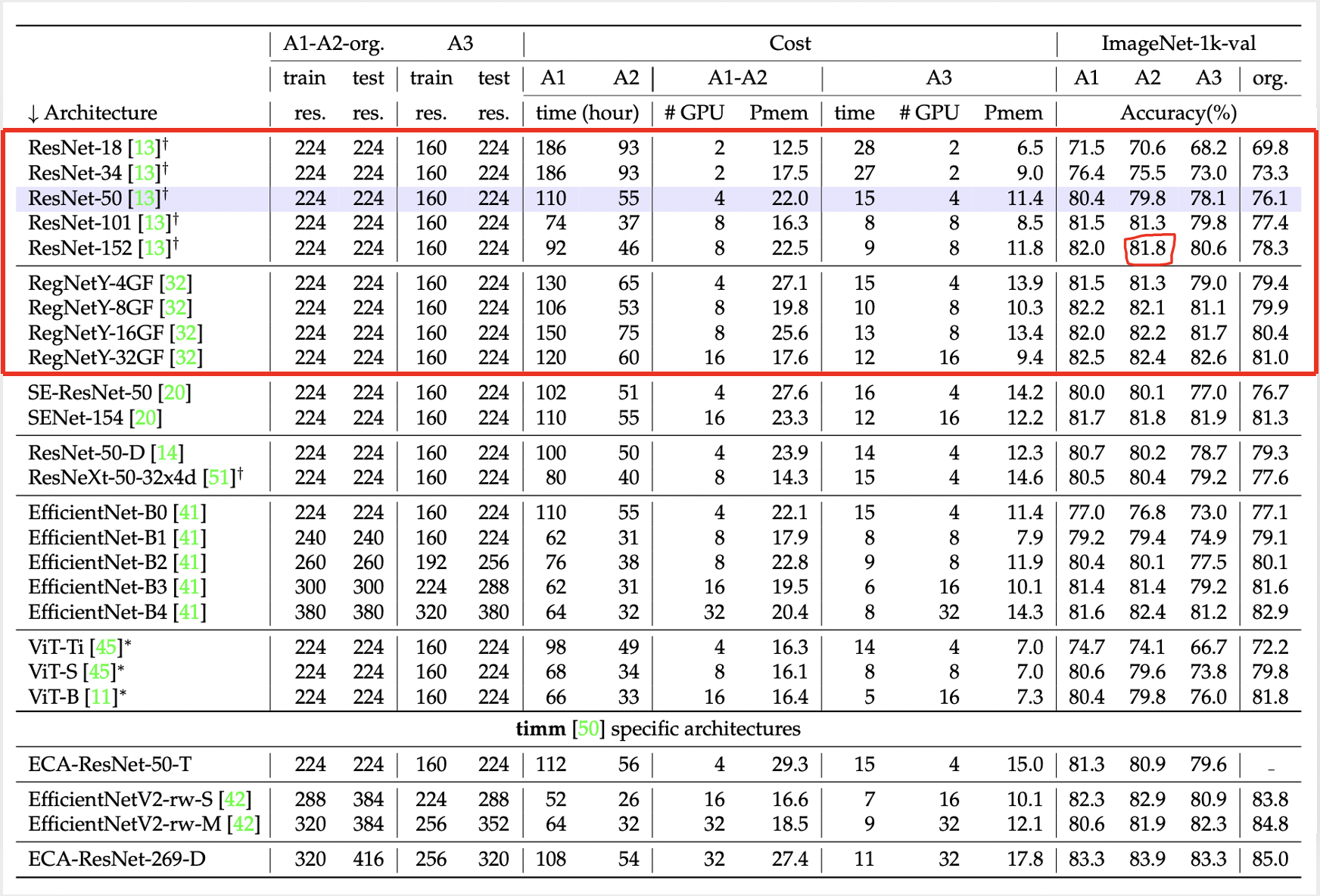
The below table shows distinct models performances with the three training procedures A1, A2, and A3. These procedures have helped to improve models from the past and which are very similar to ResNet-50.
It is also observed that increasing regularisation for training procedure A2 with ResNet-152 improved the model accuracy from 81.8 to 82.4 on a test resolution 224 X 224 and 82.7% on resolution 256 X 256. So it is important to tweak the training procedures based on the model type and size.
Experiments with Seed
It is common to read in Kaggle discussions, that an approach achieves a very high score on a particular seed. To ensure randomness in measuring the performance score, the training procedure A2 is trained with all the seeds ranging from 1 to 100.

From the above image, it is clear that the ResNet-50 model achieves a score in the range of 79.5 to 80.0 on the ImageNet 1k validation dataset.
Comparing Architectures and Training Procedures
I believe this is the most significant part of the paper. In this section, the authors compare ResNet50 and DeiT-S models of similar sizes with two different training procedures. Both the training procedures have the same epochs and batch size.
From the table, it becomes clear that each model is better than the other depending on the training schedule. This also raises an important question on the validity of comparing different models trained with different or similar procedures and concluding which model is better.

Conclusion
Resnet Strikes back is a very different paper. It ends up concluding that authors have created a gold standard model for ResNet-50 along with a modern training schedule. Along with the model, the insight to take away from the paper is a training schedule that may work amazingly well for one model may not be best suited for another model.
If you have enjoyed the blog, I will recommend reading the original paper.