
When working on Deep learning projects getting the right pipeline starting from data processing to creating predictions is a nontrivial task. In the last few years, several frameworks were built on top of popular deep learning frameworks like TensorFlow and PyTorch to accelerate building these pipelines. In this blog, we will explore how we can use one of the popular frameworks fastai2 which is currently in the early release but the high-level API is stable for us to use.

About fastai2
One of the best places to know about the library is to go through the paper published by the authors of the library. Find the abstract from the paper
fastai is a deep learning library which provides practitioners with high-level components that can quickly and easily provide state-of-the-art results in standard deep learning domains, and provides researchers with low-level components that can be mixed and matched to build new approaches. It aims to do both things without substantial compromises in ease of use, flexibility, or performance. This is possible thanks to a carefully layered architecture, which expresses common underlying patterns of many deep learning and data processing techniques in terms of decoupled abstractions. These abstractions can be expressed concisely and clearly by leveraging the dynamism of the underlying Python language and the flexibility of the PyTorch library. fastai includes: a new type dispatch system for Python along with a semantic type hierarchy for tensors; a GPU-optimized computer vision library which can be extended in pure Python; an optimizer which refactors out the common functionality of modern optimizers into two basic pieces, allowing optimization algorithms to be implemented in 4-5 lines of code; a novel 2-way callback system that can access any part of the data, model, or optimizer and change it at any point during training; a new data block API; and much more. We have used this library to successfully create a complete deep learning course, which we were able to write more quickly than using previous approaches, and the code was more clear. The library is already in wide use in research, industry, and teaching. NB: This paper covers fastai v2, which is currently in pre-release at dev.fast.ai
What I think about using fastai/fastai2
I have been using fastai library for a few Kaggle competitions and a few commercial projects. The library helps to quickly build the pipeline required for experimentation. While doing a deep learning project, there are many places where we could go wrong and for teams starting with deep learning, using a lower-level framework like Pytorch/Tensorflow could be often difficult due to the number of places where we could go wrong. Some of the common mistakes I have done in the past or I have observed teams doing in the past are
- Not normalizing the data
- Not applying initialization to the model
- Not doing transfer learning the right way.
- Missing to apply data augmentation to the labels/masks for segmentation problems.
The fastai library ensures that many of such common mistakes do not occur and it also implements several other best practices like
- Method for finding learning rate
- Different ways to train model like one_cycle, SGDR
- Test time augmentation
- Mixed Precision
If I say its all good than probably I am lying to you. The older versions of fastai suffered from flexibility when we want to try something new. It was difficult to make changes to the framework as the underlying API was not well documented, and the library quickly grew complex as several best practices and new algorithms got implemented. The older versions of fastai provided a good high-level API and the complexity increased as we went to the lower level API. The authors and the community recognized the complexities and addressed several of these issues in the newer version of the library. I avoided using the components of the Data pipeline of the older fastai library as I found it difficult for me to work compared to the simple PyTorch dataset and data loaders. But in the latest version of fastai, the elements used for building the data pipeline called DataBlocks are very intuitive and offer way more flexibility. With little efforts, we can use them as freely as we used PyTorch datasets and data loaders but with a lot of extra advantages like separating transformations that can be applied to an item level or at a batch level. Applying at a batch level is done on a GPU and thus accelerating the data pipeline.
If you are an existing fastai user and have not tried the newer version of fastai library, by end of this blog you would realize how easier it is to build a solution which can place you anywhere between top 1 to 5% in the TGS Salt identification kaggle challenge.
About TGS Salt Identification
I am not a domain expert, so let us look at what was mentioned in Kaggle's competition page.

In simple words, identifying salt deposits are very important for oil and gas industries. Thanks to TGS and Kaggle for providing us with the dataset and platform to experiment our deep learning algorithms.
Understanding the dataset
The dataset contains seismic images and masks that show where salt deposits are found if they are present. Let's look at an example.

Some of the properties of the dataset are - Each image and mask is of size 101*101 - We have 4000 labeled examples, which is our training dataset. - We have 18000 unlabelled examples, which is our test set.
Some of the challenges we may face. - Training dataset is small. - Transfer learning using models trained on imagenet dataset may not be very effective as the images are not similar to the ones used for training imagenet models. - 1562 images have no salt. - Some of the images which contain salt are only in small proportion. There are 576 images in our training dataset containing salt deposits of less than 10 percent. - 
Build Data pipeline
From this part of the blog I refer fastaiv2 as fastai as it will make the rest of the blog relevant for the future and it is easier to read.
The most important step of training a deep learning algorithm is providing data as a batch of independent and dependent variables, in our case, it is images and masks. In Pytorch it is creating a data loader for a batch and dataset for creating a single item. In fastai, we start with something called DataBlock. DataBlock is Mid-level API, and fastai also consists of lower-level APIs like fastai dataset and data loaders which offers much more flexibility. For our use case, DataBlocks API would suffice.
Let’s do a step by step to create the DataBlock and Data loaders.
Create a Datablock
Datablock acts like a template responsible for generating steps to be followed for creating the dataset/data loaders. Let’s look at the structure of our underlying data.

From the structure, it should be clear for us that the images are under train/images and masks under train/masks directories. Now we are good to start creating our data blocks.
db = DataBlock(blocks=(ImageBlock(),MaskBlock()))
We created a minimal version of datablock, where we used something called blocks. Blocks play a key role in building data pipeline in fastai, they are different methods/transformations that we want fastai to apply on our dataset. In this example we want transformations related to Image to be applied for our independent variable and hence use ImageBlock, and for our dependent variable, we want transformations related to a mask to be applied. You may be wondering that both in this case are images so why not use ImageBlock for both dependent and independent variables. Fastai implements some of the best practices while resizing images, and for better results, images of type masks are resized using a different resample strategy called PIL.Image.NEAREST. So at a very high level, one of the important things that MaskBlock does is add a specific datatype called fastai2.vision.core.PILMask. A lot of functionality in fastai depends on these datatypes.
In the coming sections, we will see examples of how the types can impact the kind of transformation being applied.
Add Items
We can assign a function to the db.get_items . The output of this function is passed to the blocks we defined. We will assign a function called get_image_files to get_items.
get_image_filestakes the path containing images and return all the file names containing image extensions like jpeg, png.
db = DataBlock(blocks=(ImageBlock(),MaskBlock()),get_items=get_image_files)
ds = db.datasets(source=path/'images')
ds[0]
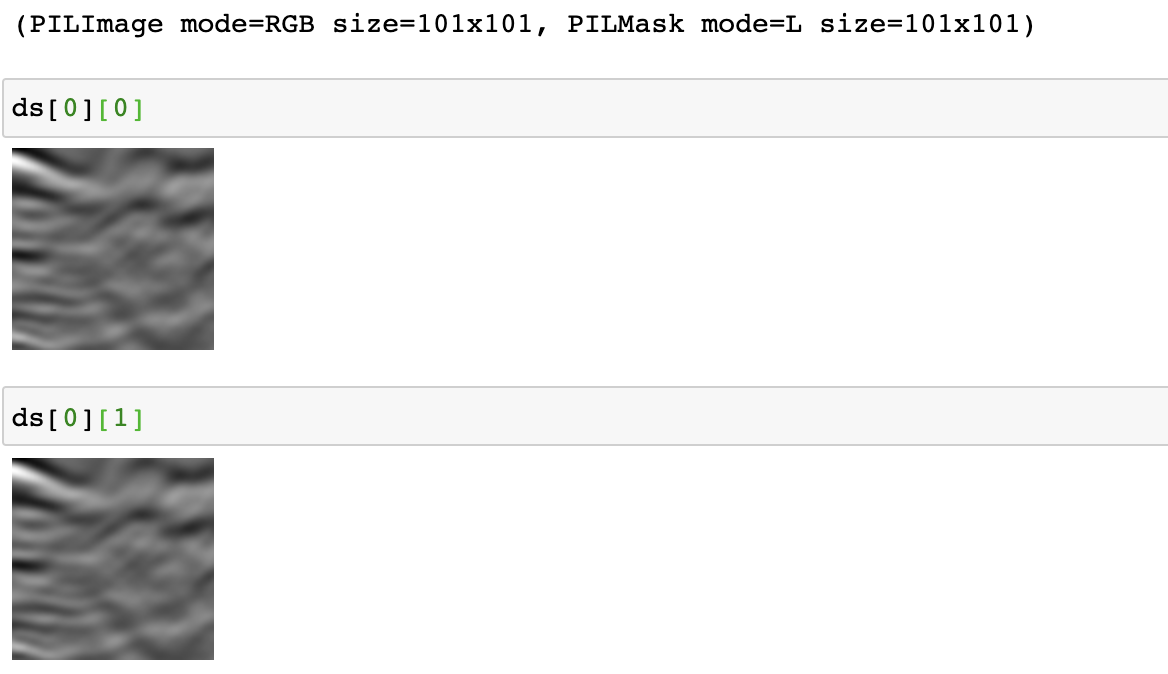
In the above code after assigning our function get_image_files which returns a fastai list (a modified version of Python List with a lot of additional features) we also created a dataset. And to this dataset, we passed the actual path containing the images and then we index on the dataset. If you have observed it, you would realize that the dependent(y) and independent variables(x) are both images as we have still not instructed how to get a mask. So both the ImageBlock and MaskBlock are given the output of the method we passed to get_items which is a file name containing the images. Now let’s see, how we can tell our data block to get both X and Y.
We got the
Xright without doing anything.
Define get_x
We can assign any function to get_x, the function is expected to return a valid input to our ImageBlock. The ImageBlock in turn calls PILImage.create which is a wrapper built around PIL.Image to handle additional types like ndarray, pytorch tensor, fastai TensorImage, bytes.
To understand more on what actually happens in PILImage.create take a look at the code.
Our function to get_x gets an item from the output from get_image_files and whatever the function returns is passed onto tranformations in the blocks. In our example it is ImageBlock for get_x and MaskBlock for get_y. Before we write a function lets look at the output for get_image_files.

We do not want to alter the output, as it is the exact input we want to pass to ImageBlock. So we can have a simple function like below.
def get_my_x(fname:Path): return fname
or use a fastai function called noop which does the exact thing.
def noop (x=None, *args, **kwargs):
"Do nothing"
return x
or do not pass any function to get_x as fastai by default passes to the ImageBlock. So our DataBlock code creation could look like this
db = DataBlock(blocks=(ImageBlock(),MaskBlock()),get_x=get_my_x,get_items=get_image_files)
or
db = DataBlock(blocks=(ImageBlock(),MaskBlock()),get_items=get_image_files)
Define get_y
If we do not specify any function for get_y then our MaskBlock will get the same input as ImageBlock which is actually the path to the image and not the mask. So let’s pass a function to get_y that generates the mask file path.
def get_my_y(fname:Path): return str(fname).replace('images','masks')
So our DataBlock would look like this now.
db = DataBlock(blocks=(ImageBlock(),MaskBlock()),get_x=get_my_x,get_y=get_my_y,get_items=get_image_files)
ds = db.datasets(source=path/'images')
So lets take a look at what our dataset contains.
imgs = [ds[0][0],ds[0][1]]
fig,axs = plt.subplots(1, 2)
for i,ax in enumerate(axs.flatten()):
ax.axis('off')
ax.imshow(imgs[i])

Data Transformations / augmentations
In fastai, data transformations are divided into 2 kinds, one done at an item level and another kind of transformation done at the batch level. In recent years it has been observed that data augmentation, data normalization take a lot of time when done on CPU, which is a standard in most cases. fastai takes effort to bring these augmentations to GPU and thus accelerating our entire pipeline. In certain cases, the underlying images are of very high definition where just reading them would cause an out of memory issue. So transformations like resizing them are done at an item level, that is on a CPU. Let’s look at the below code for how to use them.
tfms = [IntToFloatTensor(div_mask=255),Flip(),Brightness(0.1,p=0.25),Zoom(max_zoom=1.1,p=0.25),Normalize.from_stats(*imagenet_stats)]
db = DataBlock(blocks=(ImageBlock(),MaskBlock()),
batch_tfms=tfms,
item_tfms=[Resize(size,pad_mode=PadMode.Border)],
get_items=get_image_files,get_y=lambda o:str(o).replace('images','masks'))
Apart from the regular augmentation that we use, we also used a transformation called IntToFloatTensor. While discussing MaskBlock we learned that it adds a datatype for our Y as PILMask. Lets look at what is happening inside IntToFloatTensor transformation.
class IntToFloatTensor(Transform):
"Transform image to float tensor, optionally dividing by 255 (e.g. for images)."
order = 10 #Need to run after PIL transforms on the GPU
def __init__(self, div=255., div_mask=1): store_attr(self, 'div,div_mask')
def encodes(self, o:TensorImage): return o.float().div_(self.div)
def encodes(self, o:TensorMask ): return o.div_(self.div_mask).long()
def decodes(self, o:TensorImage): return ((o.clamp(0., 1.) * self.div).long()) if self.div else o
Inputs to the transformation are passed through the encodes functionality. fastai dispatch system decides to call which encodes function based on the type of input. As we can observe from the above code the default behavior is to divide the image by 255 which is a common practice while using PyTorch, but the mask is divided by 1. For our use case, we expect the Y to contain values of either 0 or 1.
So we pass on the value of div_mask of 255 to IntToFloatTensor transformation.
Dataloaders
Now we are all good to go to create data loaders using datablock that we created.
dls = db.dataloaders(path/'images',bs = bs)
The fastai data loaders come with a lot of useful functionalities like it lets you visualize batches of data using show_batch(), or pull a batch of data using one_batch() which is very useful for checking the shapes of the data and model building.
x,y = dls.one_batch()
dls.show_batch()

To be continued in part 2.
Building a data pipeline is a critical piece to building a deep learning project. We have seen how we can build one using fastai in just a few lines of code.
tfms = [IntToFloatTensor(div_mask=255),Flip(),Brightness(0.1,p=0.25),Zoom(max_zoom=1.1,p=0.25),Normalize.from_stats(*imagenet_stats)]
db = DataBlock(blocks=(ImageBlock(),MaskBlock()),
batch_tfms=tfms,
item_tfms=[Resize(size,pad_mode=PadMode.Border)],
get_items=get_image_files,get_y=lambda o:str(o).replace('images','masks'))
dls = db.dataloaders(path/'images',bs = bs)
In the next parts, we will build a custom Unet model based on resnet34/resnext50 and see how we can add features like HyperColumns, Deep supervision and classifier to build state of art models. We will also look at how to build a prediction pipeline and do test time augmentation.
If you want to quickly try out this project or use this technique for your cool project then check out JarvisCloud - A simple and affordable GPU cloud platform.