
Introduction
EfficientDet model series was introduced by Google Brain Team in 2020 which turns out to be outperforming almost every detection model of similar size in the majority of the tasks. It utilizes several optimizations. Also, many tweaks in the architecture backbone were introduced including the use of a Bi-directional Feature Pyramid Network [BiFPN] and scaling methods which resulted in the better fusion of features.
 One of the things that interest me is that it was designed using a meta-model that was trained to find the best hyper-parameters of the trained model automatically. As the name already suggests, the efficientdet model is based on the Efficientnet model as a backbone. Let’s get into further depth.
One of the things that interest me is that it was designed using a meta-model that was trained to find the best hyper-parameters of the trained model automatically. As the name already suggests, the efficientdet model is based on the Efficientnet model as a backbone. Let’s get into further depth.
EfficientDet Implementation in PyTorch is available on Github.
The original paper by Mingxing Tan, Ruoming Pang, Quoc V. Le is here EfficientDet Scalable and Efficient Object Detection.
Nowadays, Several Transformer based models have come into the picture which surpasses almost every object detection model. Yet, EfficientDet models are still widely preferred because of their efficiency and faster training without compromising much of the results.
Architecture
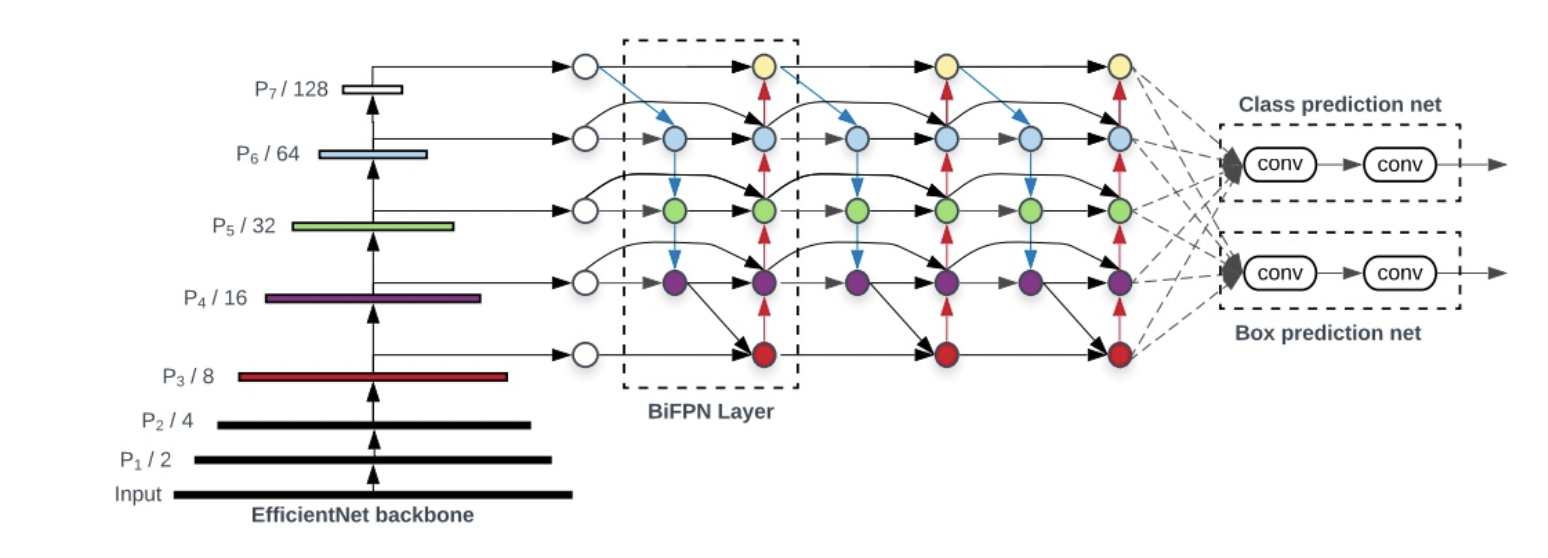
As you can see, there are 3 Major building blocks in the architecture:
A backbone block
A multi-scale features fusion block
A class and bounding box network block
Backbone Block
The main purpose of using a backbone is that it extracts features from a given image which are further passed into a feature fusion block. The backbone is completely inspired by one of the most popular Convolutional Neural Network EfficientNet which was also published by Google brain a few years back.
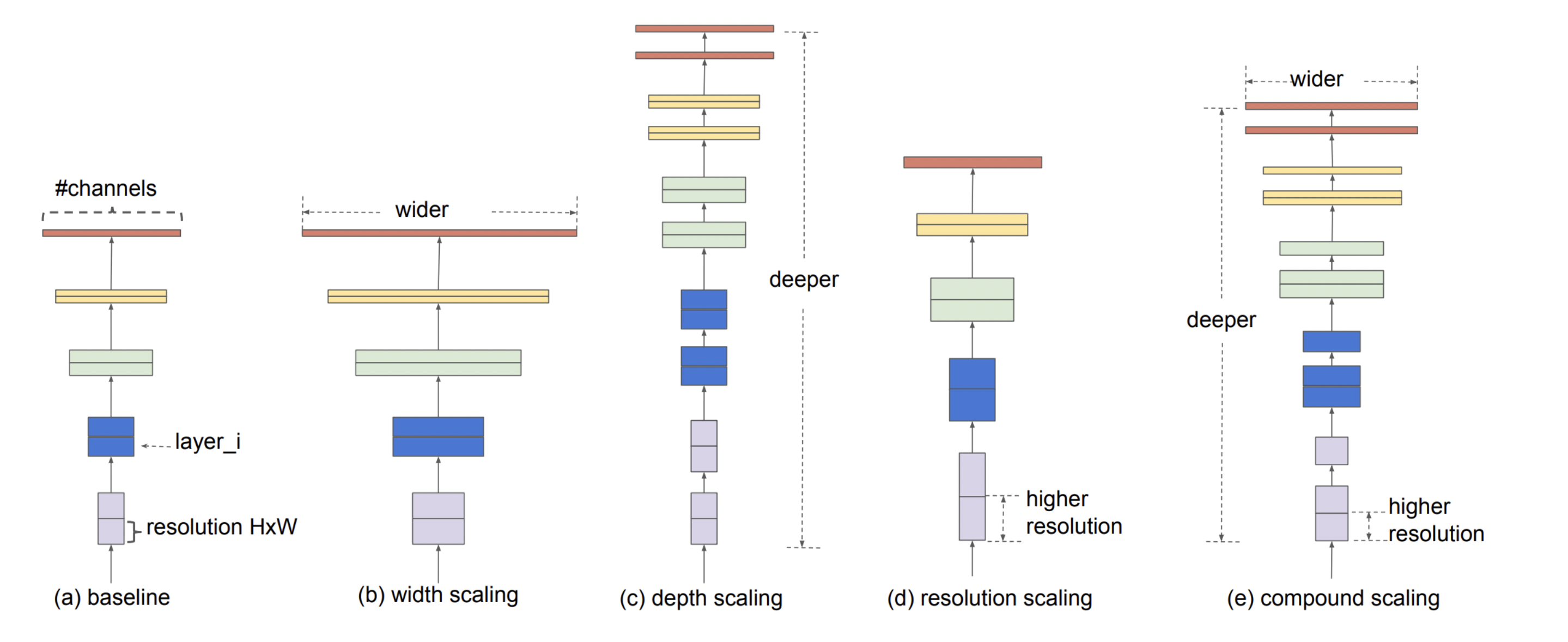
The EfficientNet proposed a new scaling method called Compound Scaling as shown in the above figure that uniformly scales all dimensions of depth, width, and resolution of the network. It was done with the help of a neural architecture search to design a new baseline network. Unlike conventional practice that arbitrary scales these factors, the EfficientNet scaling method uniformly scales network width, depth, and resolution with a set of fixed scaling coefficients. This resulted in much better efficiency and performance compared to other CNN architectures.
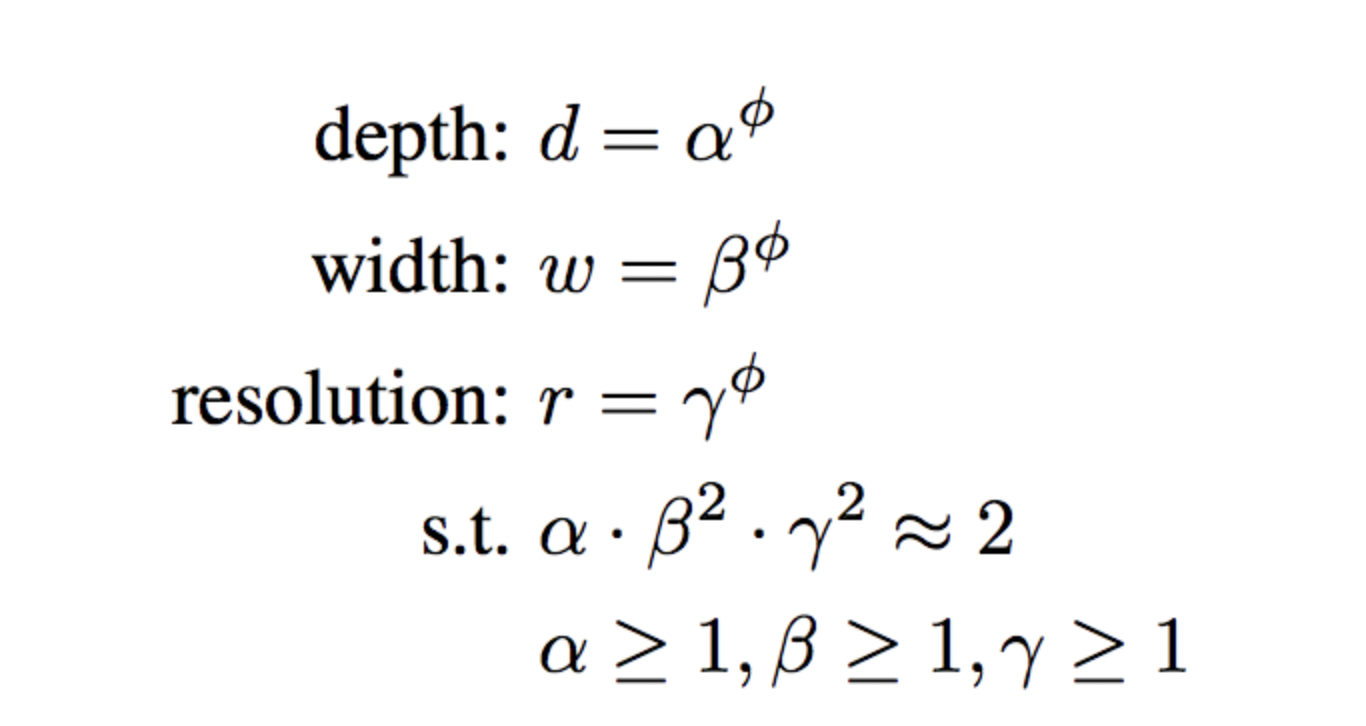
The proposed Compound scaling was a simple yet very effective scaling technique that uses a compound coefficient ɸ to uniformly scale network in a principled way. In the above equations, ɸ is a user-specified coefficient whereas α, β, and γ specify how to assign this to network depth, width, and resolution respectively.
Not limited to Efficientnet architectures, compound scaling proved its effectiveness in other architectures as well by improving imagenet accuracy by 0.7% in Resnet, 1.4 % in mobilenet, etc.
EfficientNets give better performance with fewer parameters than existing counterparts. It also exceeds others in transfer learning benchmarks. This made it a suitable backbone for the EfficientDet model.
Multi-scale features fusion block (BiFPN)
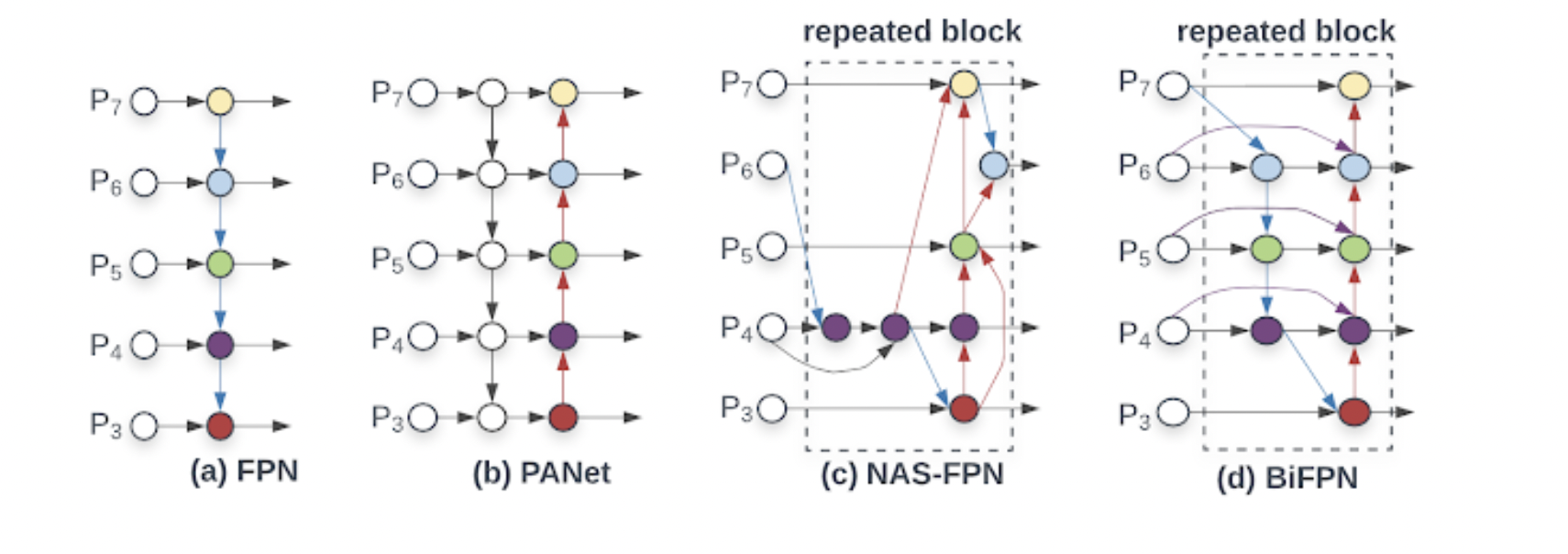
The extracted features from the backbone of the model are passed into the fusion layers. As stated in the beginning, BiFPN stands for Bidirectional Feature Pyramid Network. BiFPN was introduced to advance the mechanism of feature fusion blocks. The idea turns out to be an improved version of NAS-FPN. For further improvement in the fusion method, depthwise separable convolutions were used instead of regular convolution, meaning each input channel is convolved with a different kernel.
BiFPN improves cross-scale connections by deleting nodes with only one input edge, adding an extra edge from the original input to the output node based on some level conditions, and treating each bidirectional path as a single feature network layer.
As different input features have varied resolutions, they typically contribute unequally to the output feature. To address this problem, additional weight is applied to each input, allowing the network to learn the relative relevance of each input attribute.
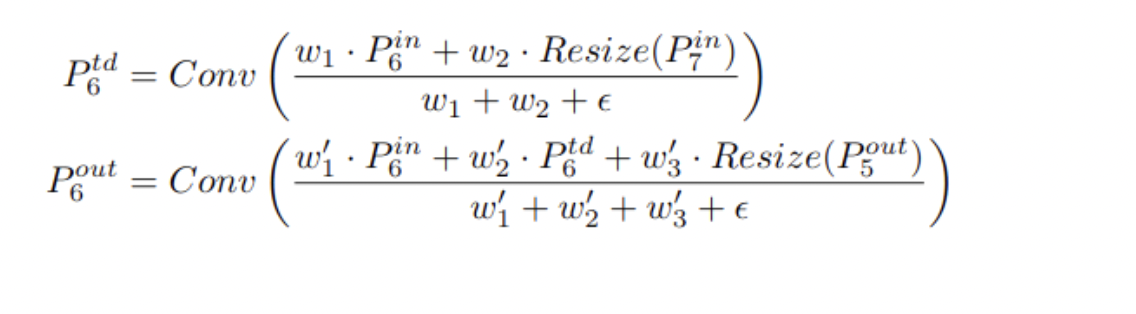
Three weighted fusion approaches were considered:
- Unbounded Fusion
- Softmax Based Fusion
- Fast Normalized Fusion
All of these techniques contribute to the BiFPN layer's efficiency and accuracy. The EfficientDet method consists of multiple stacked weighted BiFPN blocks. The number of blocks varies in the model scaling procedure.
Class and bounding box network block
The fused features from the fusion block are fed to a class and box network to produce object class and bounding box predictions respectively. This is accomplished with the help of two fully-connected layers before getting the final values. Each of the two networks takes as input all the outputs of the previous BiFPN layer. One layer is used for predicting the coordinates of the bounding box while the other one for predicting the class along with its confidence scores.
Following the BiFPN stack, we have a feature map with dimensions of B x C x H x W. Where H and W are the height and width of the feature map, C and B denote the number of channels and Batch Size respectively. The bounding boxes are then computed for each pixel in the feature map using one convolution. n anchors - rescaled and displaced versions of reference boxes - are predicted by the model. n anchors x 4 equals the number of output convolution channels. Each box has four channels for its placement and scale. Another convolution predicts the probabilities of a class for each particular location on the grid. The number of output convolution channels is the number of pixels and the outputs are just the logits as for the classification problem.
EfficientDet Evaluation On COCO Dataset
The COCO(Common Objects in Context) dataset is well-understood by state-of-the-art neural networks for applications including object detection, segmentation, and captioning. Its adaptability and image variety makes it ideal for training and benchmarking computer vision models for comparisons. COCO is considered to be the general-purpose challenge for object detection.
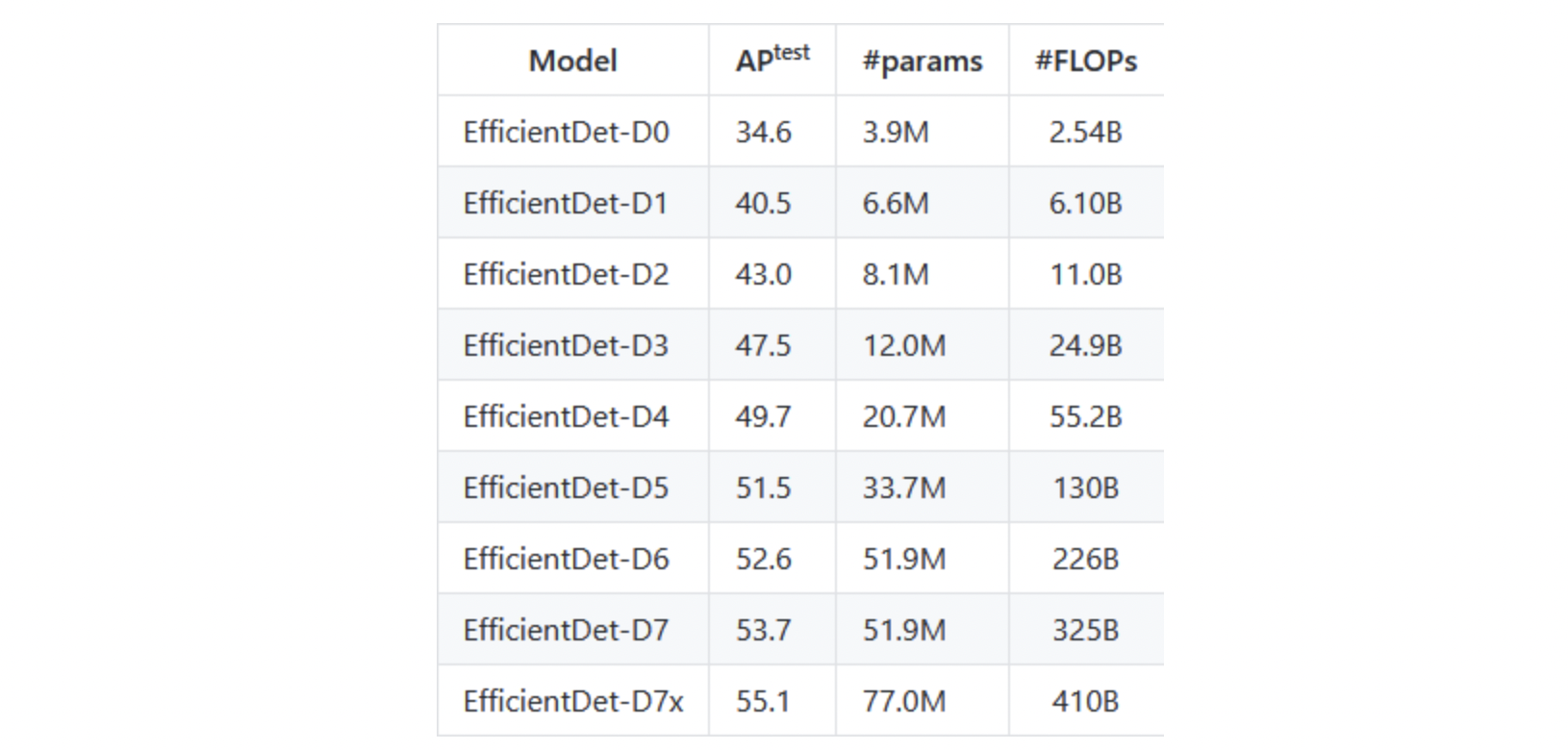
The EfficientDet Model is evaluated on the COCO data set. EfficientDet outperforms previous object detection models under several constraints.
Implementing EfficientDet in PyTorch
The following code is inspired from the original Wrightsman's efficientdet pytorch Github Repo and was used as part of one of our winning solutions in the SIIM-FISABIO-RSNA COVID 19 Detection competition.
Installing Packages & Setting up Seed
Import Data Files
Import competition CSV file consisting of Bounding Box labels and split kfolds.
FOLD = 0
marking = pd.read_csv("../input/siim-covid-mmdetection-coco-json/csv/grouped_df.csv")
marking.bboxes = marking.bboxes.map(lambda x : ast.literal_eval(x))
marking = marking.loc[marking.label == 'opacity']
train_data = marking.query(f'kfold!={FOLD}').reset_index(drop=True, inplace=False)
eval_data = marking.query(f'kfold=={FOLD}').reset_index(drop=True, inplace=False)
Creating A DataSet Class & Adding Augmentations
Normally, we would establish a PyTorch dataset to send this data into the training loop. However, some of this code, such as normalizing the image and translating the labels into the appropriate format, is not unique to this situation and must be applied regardless of which dataset is used.
Different Augmentations and normalization is performed on images of the training dataset.
Furthermore, boxes labels are converted into yxyx format for passing into the model.
train_transforms = albu.Compose([
albu.HorizontalFlip(p=0.5),
albu.ShiftScaleRotate(shift_limit=0.1, scale_limit=0.15, rotate_limit=25, p=0.60),
albu.RandomBrightnessContrast(0.15, 0.15, p=0.5),
albu.Resize(width=SZ, height=SZ, p=1.0),
albu.Normalize(mean=IMAGENET_DEFAULT_MEAN, std=IMAGENET_DEFAULT_STD, p=1.0),
ToTensorV2(p=1.0),
], bbox_params=albu.BboxParams(format='albumentations', label_fields=['labels']))
valid_transforms = albu.Compose([
albu.Resize(width=SZ, height=SZ, p=1.0),
albu.Normalize(mean=IMAGENET_DEFAULT_MEAN, std=IMAGENET_DEFAULT_STD, p=1.0),
ToTensorV2(p=1.0),
], bbox_params=albu.BboxParams(format='albumentations', label_fields=['labels']))
class DetectionDatset(Dataset):
"""Object Detection Dataset"""
def __init__(self, root: str, frame: pd.DataFrame, augmentations: albu.Compose):
self.root = Path(root)
self.data = frame
self.augmentations = augmentations
def __len__(self):
return len(self.data)
def __getitem__(self, index: int):
image_id = self.data['image_id'][index]
image_path = self.root / f"{image_id}.png"]'p
image = cv2.cvtColor(cv2.imread(str(image_path)), cv2.COLOR_BGR2RGB)
bboxes = self.data['bboxes'][index]
bboxes = np.array(bboxes)
labels = np.ones((bboxes.shape[0],), dtype=np.int64)
for i in range(50):
transformed = self.augmentations(image=image, bboxes=bboxes.tolist(), labels=labels)
if len(transformed['bboxes']) > 0:
break
image = transformed['image']
bbs = transformed['bboxes']
labels = transformed['labels']
bbs = albu.convert_bboxes_from_albumentations(bbs, 'pascal_voc', SZ, SZ)
# convert boxes to yxyx format
bboxes = []
for bbox in bbs:
x1, y1, x2, y2 = bbox
bboxes.append([y1, x1, y2, x2])
ann = {}
ann['bbox'] = torch.as_tensor(bboxes, dtype=torch.float32)
ann['cls'] = torch.as_tensor(labels, dtype=torch.int64)
assert ann['bbox'].shape[0] == ann['cls'].shape[0]
return image, ann, image_id
Loading Image Files
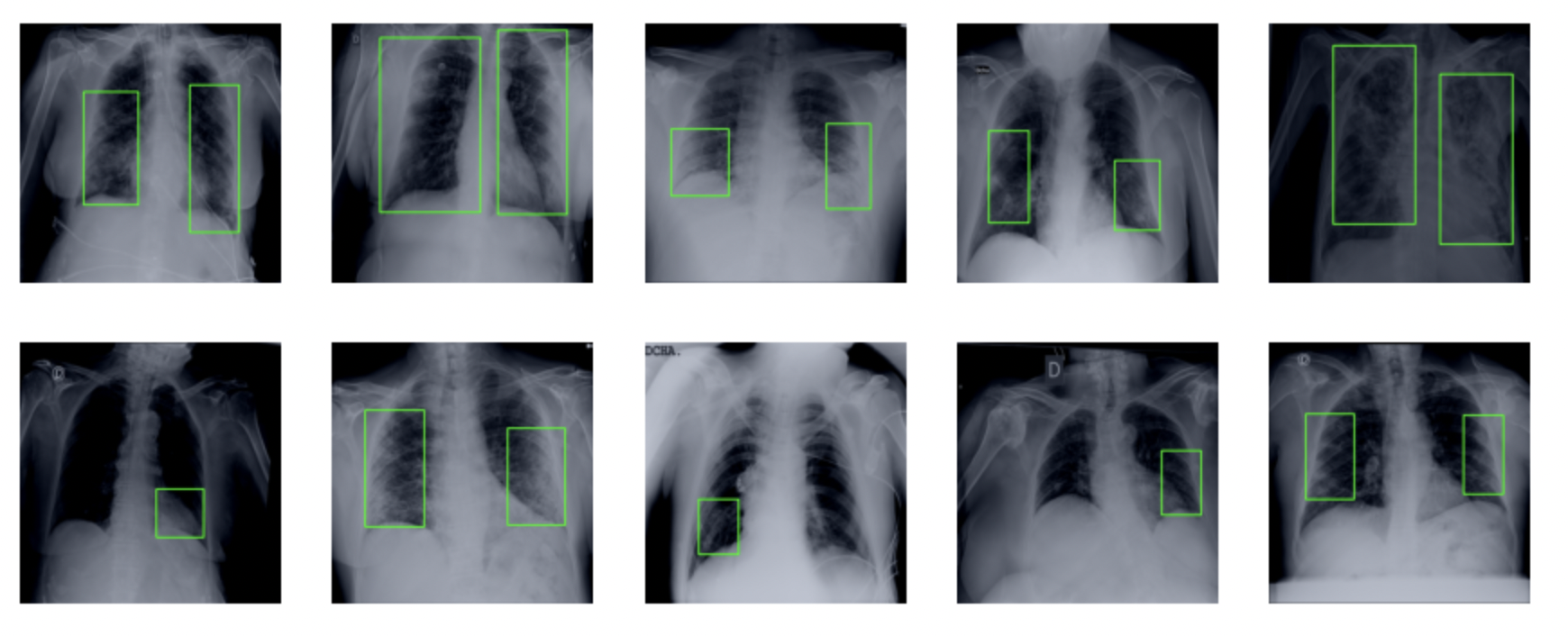
Training and evaluation data is being loaded with the help of the Dataset class defined above. Of them, ten images along with their true bounding boxes are showcased with the given code.
root = '../input/siim-covid19-png-1024px/train/'
train_dataset = DetectionDatset(root, train_data, train_transforms)
eval_dataset = DetectionDatset(root, eval_data, valid_transforms)
images = []
for i in range(10):
image, target, image_id = eval_dataset[random.choice(range(len(eval_dataset)))]
boxes = target['bbox'].cpu().numpy().astype(np.int32)
numpy_image = image.permute(1,2,0).cpu().numpy()
numpy_image *= np.array(IMAGENET_DEFAULT_STD)
numpy_image += np.array(IMAGENET_DEFAULT_STD)
numpy_image = np.clip(numpy_image, 0, 1)
for box in boxes:
cv2.rectangle(numpy_image, (box[1], box[0]), (box[3], box[2]), (0, 1, 0), 3)
images.append(numpy_image.astype(np.float))
show_images(images, nrows=2, ncols=5)
DataLoader
Using PyTorch inbuilt utils function DataLoader to load Datasets in batches for passing into efficientdet directly.
train_dataloader = DataLoader(
dataset=train_dataset,
batch_size=4,
shuffle=True,
num_workers=2,
collate_fn=lambda batch: tuple(zip(*batch)),
worker_init_fn=seed_worker,
generator=torch_generator,
)
eval_dataloader = DataLoader(
dataset=eval_dataset,
batch_size=4,
shuffle=False,
num_workers=2,
collate_fn=lambda batch: tuple(zip(*batch)),
)
Training Class
A common all-in-one class is built for multitasking including several functions.
- train_one_epoch [as the function name suggest, it’s used to train a model and return different train losses in a dictionary]
- Validate [validating the model after every epoch, save if validation loss is better than best loss so far]
- train [Loop to run the model for n number of epochs]
classTrainer:
def __init__(self, model, train_dataloader, eval_dataloader, num_epochs: int):
exp_name = '-'.join([
datetime.now().strftime("%Y%m%d-%H%M%S"),
model.config.name
])
device='cuda:0' if torch.cuda.is_available() else 'cpu'
self.epoch = 0
self.base_dir = f'./{exp_name}'
ifnot os.path.exists(self.base_dir):
os.makedirs(self.base_dir)
log_dir = "{}/log.txt".format(self.base_dir)
setup_default_logging(log_path=log_dir)
self.logging = logging.getLogger(__name__)
self.logging.info(f"Logs will be written to:{log_dir}")
self.best_summary_loss = np.Inf
self.device = device
self.model = model.to(self.device)
self.logging.info('Model:%s , param count:%d' % (self.model.config.name, sum([m.numel() for min model.parameters()])))
self.train_dataloader = train_dataloader
self.eval_dataloader = eval_dataloader
self.num_epochs = num_epochs
self.autocast = torch.cuda.amp.autocast()
self.scaler = torch.cuda.amp.GradScaler()
self.logging.info('Using native Torch AMP. Training in mixed precision.')
param_optimizer = list(self.model.named_parameters())
no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, pin param_optimizer ifnot any(ndin n for ndin no_decay)], 'weight_decay': 0.001},
{'params': [p for n, pin param_optimizer if any(ndin n for ndin no_decay)], 'weight_decay': 0.0}
]
self.optimizer = optim.AdamW(optimizer_grouped_parameters, lr=2e-03)
steps = self.num_epochs * len(self.train_dataloader)
warmup_steps = int(0.1 * steps)
self.scheduler = get_cosine_schedule_with_warmup(self.optimizer, warmup_steps, steps)
def train(self):
steps_per_epoch = (len(self.train_dataloader) + len(self.eval_dataloader))
total_steps = self.num_epochs * steps_per_epoch
self.logging.info(f'Max iterations ={total_steps}')
self.tqdm_bar = tqdm(dynamic_ncols=True, total=total_steps)
self.epoch = 0
for epoch in range(self.num_epochs):
t = time.time()
train_summary = self.train_one_epoch()
self.logging.info(
"Train: [{:>3d}/{}] "
"loss:{loss:>9.6f} "
"box_loss:{box_loss:>9.6f} "
"cls_loss:{cls_loss:>9.6f} "
"time:{epoch_time:.5f}s ".format(
self.epoch, self.num_epochs,
loss=train_summary['loss'],
box_loss=train_summary['box_loss'],
cls_loss=train_summary['cls_loss'],
epoch_time=(time.time() - t)))
self.save(f'{self.base_dir}/last.pth.tar')
t = time.time()
eval_summary = self.validate()
self.logging.info(
"Eval : [{:>3d}/{}] "
"loss:{loss:>9.6f} "
"box_loss:{box_loss:>9.6f} "
"cls_loss:{cls_loss:>9.6f} "
"time:{epoch_time:.5f}s ".format(
self.epoch, self.num_epochs,
loss=eval_summary['loss'],
box_loss=eval_summary['box_loss'],
cls_loss=eval_summary['cls_loss'],
epoch_time=(time.time() - t)))
if eval_summary['loss'] <a self.best_summary_loss:
self.best_summary_loss = eval_summary['loss']
self.model.eval()
self.save(f'{self.base_dir}/best.pth.tar')
self.epoch += 1
@torch.no_grad()
def validate(self):
self.tqdm_bar.set_postfix_str('Validation')
self.model.eval()
losses_m = AverageMeter()
box_losses_m = AverageMeter()
cls_losses_m = AverageMeter()
for batchin self.eval_dataloader:
image, ann, _ = batch
images = torch.stack(image)
inputs = images.to(self.device).float()
target = {}
target['bbox'] = [a['bbox'].to(self.device) for ain ann]
target['cls'] = [a['cls'].to(self.device) for ain ann]
target['img_scale'] = None
target['img_size'] = None
output = model(inputs, target)
loss = output['loss']
cls_loss = output['class_loss']
box_loss = output['box_loss']
detections = output['detections']
# [x_min, y_min, x_max, y_max, score, class]
losses_m.update(loss.item(), inputs.size(0))
box_losses_m.update(box_loss.item(), inputs.size(0))
cls_losses_m.update(cls_loss.item(), inputs.size(0))
self.tqdm_bar.update(1)
return OrderedDict([('loss', losses_m.avg), ('box_loss', box_losses_m.avg), ('cls_loss', cls_losses_m.avg)])
def train_one_epoch(self):
self.tqdm_bar.set_postfix_str('Training')
self.model.train()
losses_m = AverageMeter()
box_losses_m = AverageMeter()
cls_losses_m = AverageMeter()
for batch_num, batchin enumerate(self.train_dataloader):
image, ann, _ = batch
images = torch.stack(image)
inputs = images.to(self.device).float()
target = {}
target['bbox'] = [a['bbox'].to(self.device) for ain ann]
target['cls'] = [a['cls'].to(self.device) for ain ann]
with self.autocast:
output = model(inputs, target)
loss = output['loss']
cls_loss = output['class_loss']
box_loss = output['box_loss']
losses_m.update(loss.item(), inputs.size(0))
box_losses_m.update(box_loss.item(), inputs.size(0))
cls_losses_m.update(cls_loss.item(), inputs.size(0))
self.optimizer.zero_grad()
self.scaler.scale(loss).backward()
self.scaler.unscale_(self.optimizer)
torch.nn.utils.clip_grad_norm_(self.model.parameters(), 10)
self.scaler.step(self.optimizer)
self.scaler.update()
self.scheduler.step()
lrl = [param_group['lr'] for param_groupin self.optimizer.param_groups]
lr = sum(lrl) / len(lrl)
summary_string = (
"Epoch:{epoch} "
"total_loss: ({loss.avg:>6.4f}) "
"box_loss: ({box_loss.avg:>6.4f}) "
"cls_loss: ({cls_loss.avg:>6.4f}) "
"LR:{lr:.3e} ".format(
epoch=self.epoch,
loss=losses_m,
box_loss=box_losses_m,
cls_loss=cls_losses_m,
lr=lr,
))
self.tqdm_bar.set_description(summary_string)
self.tqdm_bar.update(1)
return OrderedDict([('loss', losses_m.avg), ('box_loss', box_losses_m.avg), ('cls_loss', cls_losses_m.avg)])
def save(self, path):
self.model.eval()
torch.save({
'model_state_dict': self.model.model.state_dict(),
'optimizer_state_dict': self.optimizer.state_dict(),
'scheduler_state_dict': self.scheduler.state_dict(),
'best_summary_loss': self.best_summary_loss,
'epoch': self.epoch,
}, path)
Loading Model & Training
Efficientdet model is loaded using the create_model function by Wrightsman and run using the Trainer Class for 10 epochs. The best model’s state dictionary will be saved based on validation loss.
model = create_model(
model_name=MODEL,
bench_task='train',
num_classes=1,
pretrained=True,
bench_labeler=True,
)
trainer = Trainer(model, train_dataloader, eval_dataloader, num_epochs=10)
trainer.train()
Inference
@torch.no_grad()
def make_predictions(dl, net, score_threshold=0.05):
"""predictions for original images"""predictions = {}
for batchin tqdm(dl, dynamic_ncols=True, smoothing=0):
image, ann, image_id = batch
images = torch.stack(image).cuda().float()
target = {}
target['img_scale'] = torch.tensor([1]*images.shape[0]).float().cuda()
target['img_size'] = torch.tensor([a['img_size'] for ain ann]).cuda().float()
det = net(images, img_info=target)
for iin range(images.shape[0]):
boxes = det[i].detach().cpu().numpy()[:,:4]
scores = det[i].detach().cpu().numpy()[:,4]
indexes= np.where(scores > score_threshold)[0]
boxes, scores = boxes[indexes], scores[indexes]
predictions[image_id[i]] = ({'boxes': boxes, 'scores': scores})
return predictions
def load_model(state_dict):
bench = create_model(
model_name=MODEL,
bench_task='predict',
num_classes=1,
bench_labeler=True,
soft_nms=False,
pretrained_backbone=False,
image_size=[SZ, SZ])
load_checkpoint(unwrap_bench(bench), state_dict, use_ema= False)
bench.cuda()
bench.eval()
return bench
Functions were defined to load model and make predictions on new unseen test dataste directly.
models = load_model(checkpoint)
preds = make_predictions(dls[fold], model)
Plotting Predictions
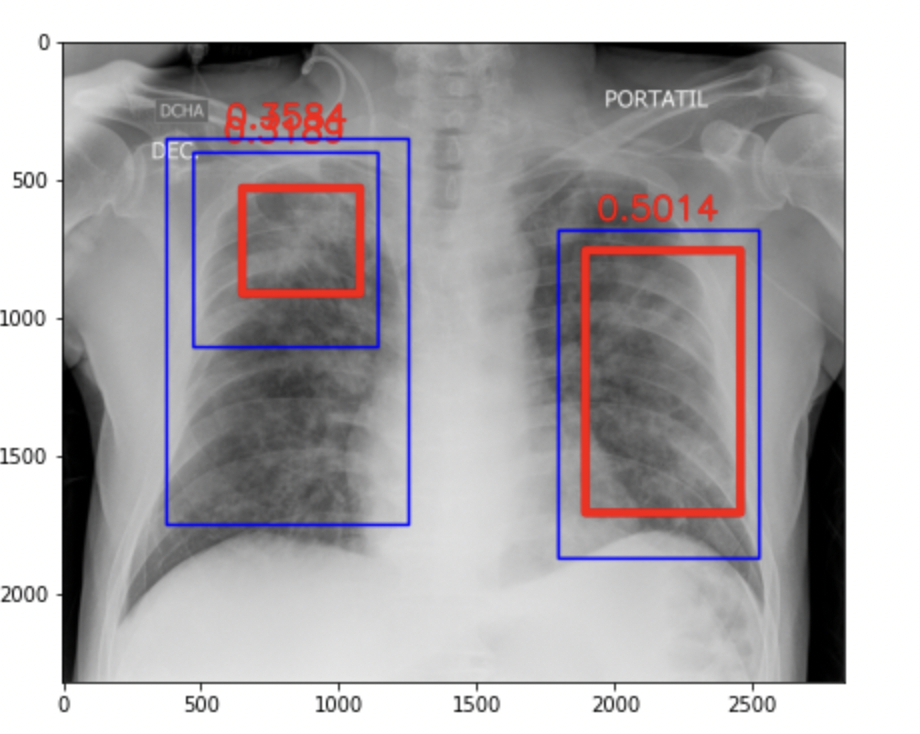
def plot_with_pred(sub,tl, image_id):
# print_study_conf(sub, image_id)path = glob(f'../input/siim-covid19-detection/train/*/*/{image_id}.dcm')[0]
img = dicom2array(path)
img = cv2.cvtColor(img,cv2.COLOR_GRAY2RGB)
pred_str = sub[sub['id'].str.startswith(image_id)].PredictionString.values[0]
true_str = tl[tl['id'].str.startswith(image_id)].label.values[0]
true_bbox = pred_str_to_confidence_box_maps(true_str)
confidence_box_maps = pred_str_to_confidence_box_maps(pred_str)
print(confidence_box_maps)
if len(confidence_box_maps) == 0:
print(f'{image_id}: There are no boxes with confidence greater than{CONF_THRESHOLD}.')
img = add_bbox(img, confidence_box_maps)
img = add_bbox2(img, true_bbox)
plot_img(img)
— Red Bboxes [True Labels]
— Blue Bboxes [Predicted Labels]
Kaggle winning Solutions using EfficientDet
Global Wheat Detection Competition
SIIM-FIASBIO-RSNA Covid19 Detection Competition Winning solutions -
Here is Tensorflow implementation of EfficientDet
Reach Out to author
If you have any doubts about the blog or would like to have a talk you can reach out to me on LinkedIn or Twitter, I would be happy to help!