
Transformers are at the heart of NLP in the current scenario. They are making great strides and producing state-of-the-art results in diverse domains ranging from Computer Vision to Graph NNs.
In this post, we will dive into the details of the Staggered Attention Mechanism introduced in the paper Investigating Efficiently Extending Transformers for Long Input Summarization by Jason Phang Yao Zhao and Peter J. Liu, researchers at Google Brain.
It thoroughly studies the practical application of Transformer models on long Input text summarization tasks, and based on their experiments, they introduce PEGASUS-X, an extended version of PEGASUS, which sets the benchmark on two long summarization datasets.
What is a long input summarization task? What is PEGASUS? What experiments did they perform? Read on to find out!
Long Input Summarization
As the name suggests, this problem involves summarizing long input documents into a short text description. Nobody likes to read long, boring texts, and this task aims to solve this. What makes this problem, so challenging is, Quadratic Scaling of the Attention Mechanism
Quadratic What?
What makes Transformers so great at what they do is the Attention Mechanism. If this is the first time you hear of it, I recommend this blog by Jay Alammar to get started. Simply stated, there are two main things you need to know -
- The text is broken up into tokens.
- Each token tries to understand all other tokens.
Let us work with an analogy, Imagine there is a party and the host decides to invite many random people. Assuming that they do not know each other beforehand, you determine how fun the party is by how well people get to know each other. How will you maximize this fun score? The best way is to ensure every person introduces himself to every other person present in the room. This is the reasoning behind Transformers!
Every token attends every other token in the sequence in the basic attention transformers. Now say your input text is very long, and you apply the attention mechanism. Can you figure out the problem here? The Party will go on for too long!
This is the Quadratic Scaling Problem. The memory requirements needed to handle the huge computations scale up quadratically and constrain the models' size.
Many Solutions have been proposed recently to solve this Problem
- Longformer (Beltagy et al., 2020)
- BigBird (Zaheer et al., 2020)
- Performer (Choromanski et al., 2020)
- Reformer (Kitaev et al., 2020)
- Linformer (Wang et al., 2020)
They all have a similar idea about reducing computation; You can get a reasonably fun party by allowing only some people to have their introductions.
Let us take the example of Longformer and BigBird. They both use the concept of Block/Group based attention.
Let me introduce this through the party analogy. Say you decide not to allow everyone to introduce themselves to each other but rather form groups of people and tell them to introduce themselves within the groups. You also need to ensure that the grouping is done intelligently enough. As the host, you have some idea about where the people are from; an easy solution is to put the people who live near each other in the same group since it's easier for them to get to know each other. Another smart idea is to have a few people who are allowed to meet all the people present to ensure that the knowledge is shared between groups.
Our Party is going great; how about we apply this to the task?
The grid below tells whether we allow one token to attend to another. The attention given on the left only allows the token Not to attend to Pay.

A full self-attention mechanism has the complete grid colored, like the one on the right. This takes up a huge amount of memory, as explained.

Local Block Attention
We can consider the nearby tokens into one block and apply block-based self-attention as shown above. As you can see, I and Can attend to each other, Not and Pay attend to each other, so on…
To introduce global knowledge sharing, we can allow some tokens to attend to all of them, a.k.a global tokens.

Global-Local Attention
Here the word Pay is a global token. Is the global token enough to allow information sharing within the groups? Can’t we do anything better?
Longformer (Beltagy et al., 2020) introduced the concept of sliding window attention. This is best explained by the figure below.

Sliding Attention
You can see how the attention window slides across the text. This type of attention is used in BigBird (Zaheer et al., 2020), along with global and some random token attention to allow knowledge sharing. To understand each of them in a detailed manner, I recommend reading this blog by Huggingface🤗.
Among all of these attention mechanisms, which one works best? Which one to use?
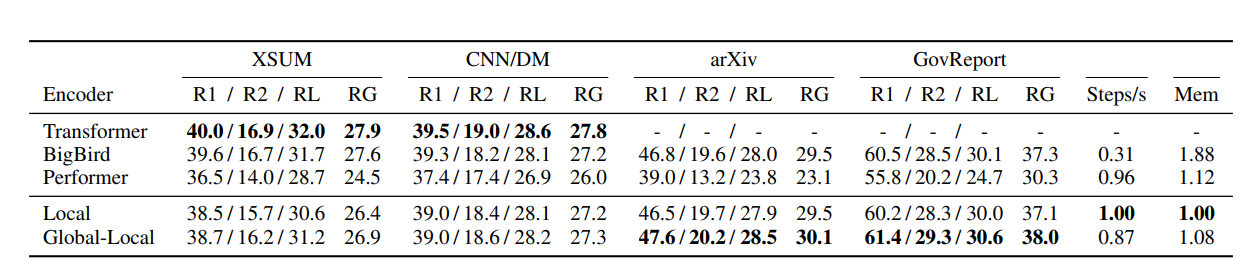
Table 1: Comparison of different encoder architectures on short (XSUM, CNN/DM) and long (arXiv, GovReport) summarization tasks. Steps/s refers to the training steps and is computed based on arXiv and normalized to Local Transformer performance.
These are the results of experiments done on attention mechanisms by the authors. Let us decode and understand this table. The paper compares the performance of the models using ROUGE, Recall-Oriented Understudy for Gisting Evaluation, metric. It is a standard metric for evaluating summarization and machine translation tasks. You can go through this video by HuggingFace🤗 to understand more.
R1, R2, RL, and RG refer to ROUGE-1, ROUGE-2, and ROUGE-L, and their Geometric average, respectively. They are calculated using this rouge-scorer package by Google. Local refers to the attention mechanism described in Figure 2, while Global-Local refers to Figure 3.
We first notice that, on Long summarization tasks, Global-Local performs much better than Local. The paper attributes this to the Global tokens, which allow information sharing. Here’s some explanation from the paper as well.
The simple local attention encoder, which uses a block-local attention mechanism, attains performance surprisingly close to that of Big Bird while being much faster and using much less memory. The Global-Local encoder trades off a small amount of speed and memory for better performance, outperforming BigBird. While both Local and Global-Local models underperform BigBird and Transformer for short tasks, it appears that the model architectures make the right trade-offs for performance on long summarization tasks. Phang et al., 2022
As it turns out, Global-Local attention is faster and performs better than BigBird for long summarization tasks. Hence the authors use this for further experiments.
But can we do any better?
Let us talk about two new implementation ideas suggested in the paper.
Staggered Block-Local Attention
Transformer Encoders consist of multiple attention layers. At each layer, a different attention matrix is computed. If we use the block-local attention mechanism (Figure 2), information is not shared across blocks throughout the encoder.
Imagine different layers of encoders as different events at the party, and at every event, you form groups of people to let them know each other. Now, if you form the same groups at every event, you will have the same set of people getting to know each other more and more, but that won’t do much for your fun score; you need to allow more people to interact.
This paper suggests a simple solution to shuffle up the groups at every event at the party. This will ensure that new people interact at every event and raise your fun score!
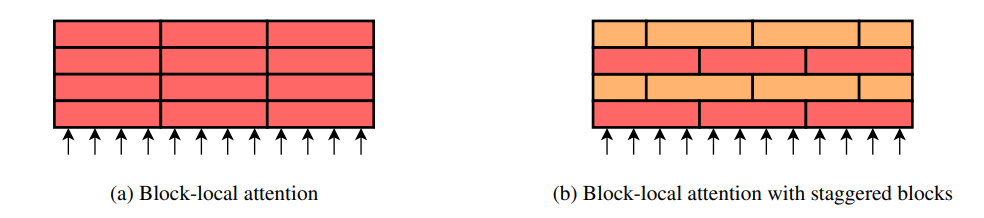
Source : Research paper
In the figure above, consider different arrows as your tokens, and you split them into blocks at each layer. In the Block-local attention mechanism, you allow the same groups at each layer, whereas, in the staggering attention, you shift the blocks at alternating layers to allow information exchange.
Feeding Global representations to Decoder
Transformer Models consist of Encoders and Decoders. Encoders are responsible for understanding the language representations and generating context vectors, using which the Decoders decode the output sequence. It is easy to see that the better the context vectors, a.k.a, information transmission between encoder and decoder, the better the decoded output.
In a vanilla transformer, the decoder only attends to the encoded token representations and not the global token representations. In this paper, the authors propose a variant that supplies the global token representations to the decoder and introduces a second transmission between encoder and decoder that only transmits global token information.
Our goal is to allow the decoder to incorporate global information before cross-attention over the encoded sequence. Phang et al., 2022
Finally, let us see the results of these two approaches
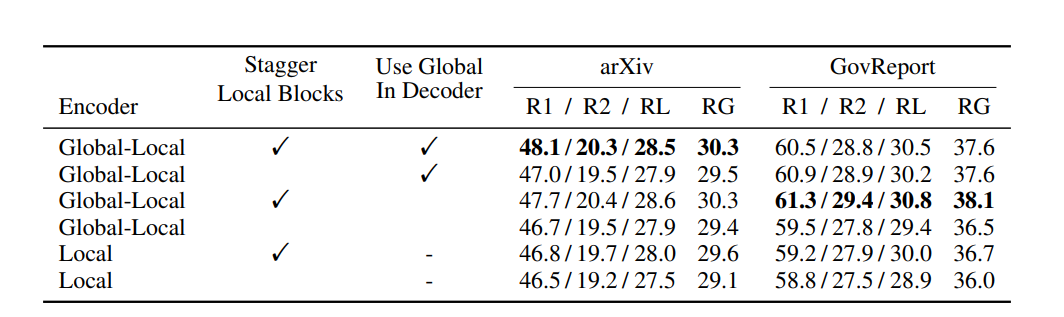
Table 2: Results of the two implementation ideas on the Global-Local and Local attention mechanism.
We can see that staggering the local blocks improves performance for both Local and Global-Local Encoder architectures. It is surprising that staggering, which was introduced to allow information sharing between groups, improves performance even for Global-Local attention, where there are already global tokens. Hence, using both of them gives a noticeable boost to performance.
Global-Local: Block size and Number of Global Tokens
In Figure 3, The block size for the text was two, and only one Global token was present. But is this the case for real implementations as well? Of course not!
The Authors experiment with varying block sizes and Global tokens to find the best tradeoff between performance and computation time. How did computation come into the picture? Think of what will happen if your block size equals your token length. The mechanism will turn out to be the same as the full attention mechanism!
Luckily, the authors find that the effect saturates with increasing block size.
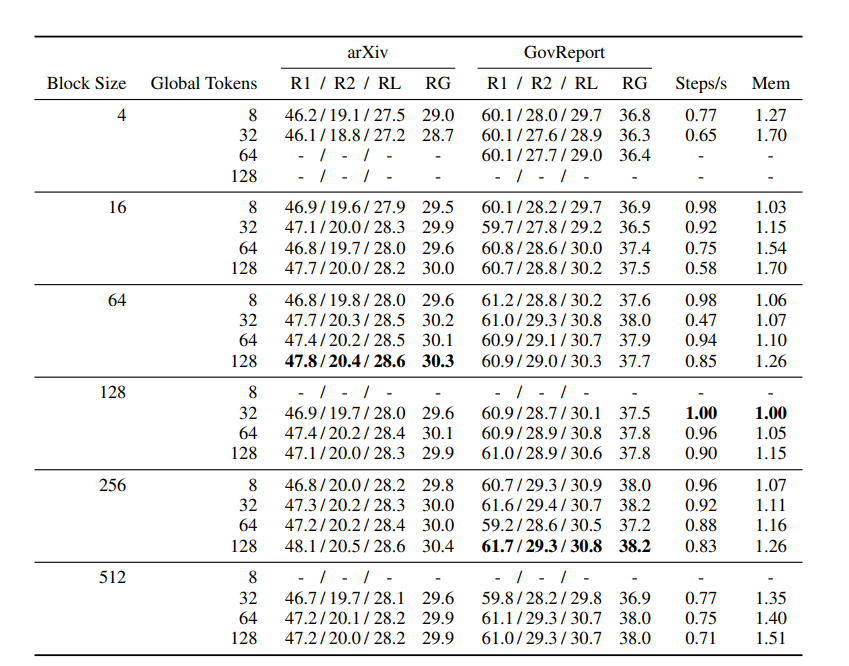
Table 3: Results of Varying the Block-size and Global Token size of Global-Local Encoder.
It is a huge table, but the main part is bolded for us. The best performance on arXiv is achieved with only 64 block size and 128 Global Tokens, while on GovReport with 256 block size and 128 Global tokens.
Increasing either of these hyperparameters is preferable if resources allow but may not be a high priority compared to other potential model improvements. Phang et al., 2022
Hence, the Staggered Attention mechanism proved superior to the previously proposed architectures to handle long input sequences. The paper studies attention mechanisms, and Positional encodings pretraining schemes and derives the best out of everything to reach the state-of-the-art in long input summarization.